
机器学习常常依赖复杂模型,而这些模型往往像黑箱一样运作,使解释变得困难。特征分量分析(Eigen-Component Analysis,ECA)从量子理论中汲取灵感,为分类和聚类构建可解释的线性模型。本文介绍其核心思想,展示基本用法,并概述 eigen-analysis 包暴露的主要参数。
Table of Contents
什么是特征分量分析?
特征分量分析将受量子理论启发的思想用于创建面向分类和聚类的线性模型。不同于许多依赖大量预处理的传统方法,ECA 的设计目标是在不要求数据中心化或标准化的情况下工作,这可以简化工作流程,并让学习到的表示更容易检查。
ECA 的核心吸引力在于可解释性。模型通过特征分量暴露特征到类别的映射,使研究人员和数据科学家能够检查预测或聚类分配背后的原因。
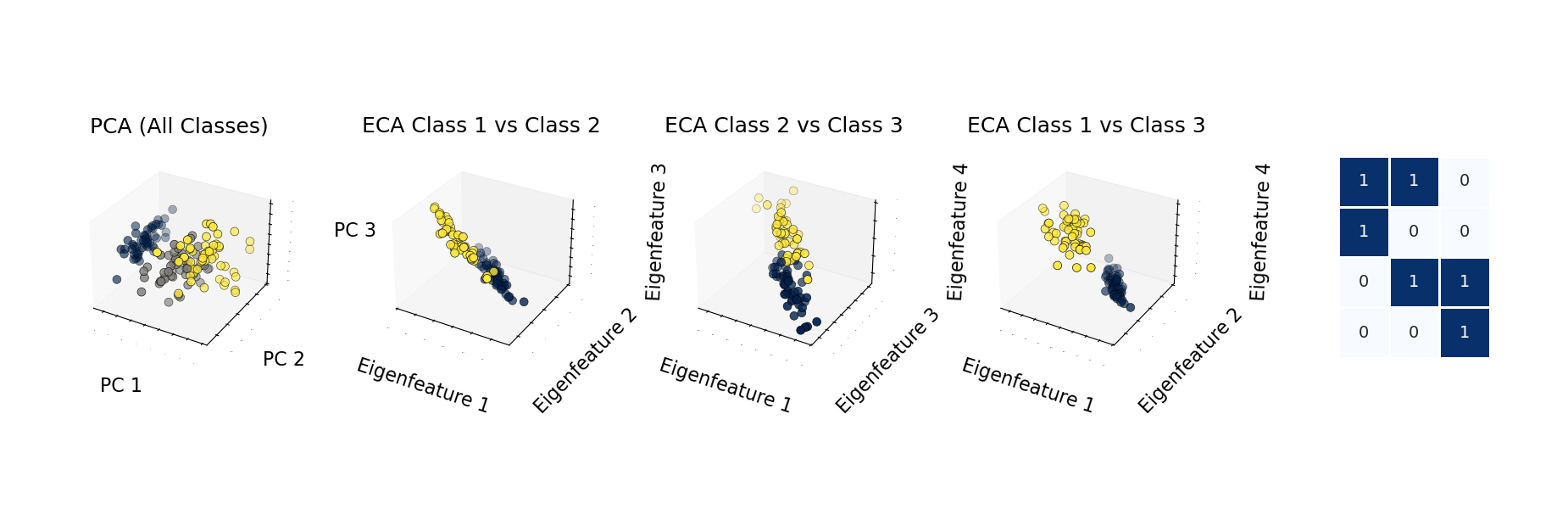
主要特性与优势
ECA 将理论结构与实用的 Python 实现结合起来:
- 兼容 scikit-learn 的接口:该包实现了熟悉的 scikit-learn Estimator API,便于已经在 Python 机器学习生态中工作的用户上手。
- 监督与无监督模式:ECA 通过相关实现
ECA和UECA支持监督分类与无监督聚类。 - PyTorch 后端:实现基于 PyTorch 构建,在有兼容 CUDA 设备时可以使用 GPU 加速。
- 可视化工具:该包包含用于特征特征、特征映射、训练曲线,以及聚类或分类结果的绘图工具。
- 数学基础:ECA 使用反对称变换矩阵来构建受量子理论结构启发的模型表示。
ECA 入门
可以从 PyPI 安装该包;如果你想检查或修改实现,也可以从源码安装:
# Installation from PyPI
pip install eigen-analysis
# Or from source
git clone https://github.com/lachlanchen/eca.git
cd eca
pip install .该包依赖常见的数据科学库,包括 NumPy、PyTorch、Matplotlib、Seaborn、scikit-learn 和 SciPy。要验证本地安装,请检查 Python 是否能够导入该包:
python - <<'PY'
import eigen_analysis
print("eigen_analysis imported successfully")
PY使用 ECA 进行分类
下面的示例在经典 Iris 数据集上训练一个 ECA 分类器:
# iris_classification.py
import traceback
import numpy as np
from eigen_analysis import ECA
from eigen_analysis.visualization import visualize_clustering_results
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Load Iris dataset.
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split data.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=23,
stratify=y,
)
# Create and train ECA model.
eca = ECA(num_clusters=3, num_epochs=10000, learning_rate=0.001)
eca.fit(X_train, y_train)
# Make predictions.
y_pred = eca.predict(X_test)
# Evaluate accuracy.
accuracy = accuracy_score(y_test, y_pred)
print(f"Test accuracy: {accuracy:.4f}")
# Get transformed data.
X_transformed = eca.transform(X_test)
# Access model components.
P_matrix = eca.P_numpy_ # Eigenfeatures
L_matrix = eca.L_numpy_ # Feature-to-class mapping
# Visualize results.
visualize_clustering_results(
X_test,
y_test,
y_pred,
eca.loss_history_,
X_transformed,
eca.num_epochs,
eca.model_,
(eca.L_numpy_ > 0.5).astype(float),
eca.L_numpy_,
eca.P_numpy_,
"Iris",
output_dir="eca_classification_results_20250418",
)
except Exception:
traceback.print_exc()这个示例遵循常见的监督学习流程:加载数据,将其划分为训练集和测试集,拟合模型,对未见数据预测标签,并检查准确率以及学习到的矩阵。
使用 UECA 进行无监督聚类
对于无监督学习任务,UECA 变体提供聚类能力:
# clustering_example.py
import traceback
import numpy as np
from eigen_analysis import UECA
from eigen_analysis.visualization import visualize_clustering_results
from sklearn.datasets import make_blobs
from sklearn.metrics import adjusted_rand_score
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Generate synthetic data.
X, y_true = make_blobs(n_samples=300, centers=3, random_state=42)
# Train UECA model. y_true is supplied here only for evaluation and visualization.
ueca = UECA(num_clusters=3, learning_rate=0.01, num_epochs=3000)
ueca.fit(X, y_true)
# Access clustering results.
clusters = ueca.labels_
remapped_clusters = ueca.remapped_labels_ # Optimal mapping to ground truth
# Evaluate clustering quality.
ari_score = adjusted_rand_score(y_true, clusters)
print(f"Adjusted Rand Index: {ari_score:.4f}")
# Visualize clustering results.
visualize_clustering_results(
X,
y_true,
remapped_clusters,
ueca.loss_history_,
ueca.transform(X),
ueca.num_epochs,
ueca.model_,
ueca.L_hard_numpy_,
ueca.L_numpy_,
ueca.P_numpy_,
"Custom Dataset",
output_dir="eca_clustering_results_20250418",
)
except Exception:
traceback.print_exc()在聚类工作中,评估取决于可用数据。如果存在真实标签,Adjusted Rand Index 等指标可以量化一致性。如果没有标签,则应检查聚类稳定性、变换后的表示,以及特定领域中的聚类质量。
高级可视化与自定义
可视化工具可以使用特征名和类别名,让图表更易解释:
# custom_visualization.py
visualize_clustering_results(
X,
y,
predictions,
loss_history,
projections,
num_epochs,
model,
L_hard,
L_soft,
P_matrix,
dataset_name="Iris",
feature_names=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"],
class_names=["Setosa", "Versicolor", "Virginica"],
output_dir="custom_visualization_20250418",
)对于 MNIST 这样的图像数据集,专门的可视化函数会展示模型如何解释类似图像的特征空间:
# mnist_example.py
import traceback
import numpy as np
from eigen_analysis import ECA
from eigen_analysis.visualization import visualize_mnist_eigenfeatures
from torchvision import datasets
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Load MNIST.
mnist_train = datasets.MNIST("data", train=True, download=True)
X_train = mnist_train.data.reshape(-1, 784).float() / 255.0
y_train = mnist_train.targets
# Train ECA model.
eca = ECA(num_clusters=10, num_epochs=1000)
eca.fit(X_train, y_train)
# Visualize MNIST eigenfeatures.
visualize_mnist_eigenfeatures(eca.model_, output_dir="mnist_results_20250418")
except Exception:
traceback.print_exc()处理更大的数据集时,请在训练前确认所选设备,并根据收敛行为调整 num_epochs 和 learning_rate:
print(f"Using device: {eca.device}")
print(f"Final loss: {eca.loss_history_[-1]:.6f}")调优模型参数
两种 ECA 变体都暴露了可针对特定数据集调优的参数。
ECA 模型:监督分类
num_clusters:类别数量。learning_rate:优化器学习率。默认值为0.001。num_epochs:训练轮数。默认值为1000。temp:sigmoid 的温度参数。默认值为10.0。random_state:用于可复现性的随机种子。device:要使用的设备,例如cpu或cuda。
UECA 模型:无监督聚类
num_clusters:簇数量。learning_rate:优化器学习率。默认值为0.01。num_epochs:训练轮数。默认值为3000。random_state:用于可复现性的随机种子。device:要使用的设备,例如cpu或cuda。
一个实用的调优循环是先从默认值开始,绘制损失曲线,然后调整学习率和训练轮数。如果损失振荡或发散,就降低学习率。如果训练结束时损失仍在下降,就增加训练轮数。
ECA 背后的科学
ECA 从量子理论中汲取灵感,创建一种具有数学结构的分类与聚类方法。其反对称变换矩阵提供了一种表示数据的方式,同时保留学习到的特征分量与类别或簇分配之间的可读关系。
对于希望在此工作基础上继续研究的人员,可以按如下方式引用该项目:
@inproceedings{chen2025eigen,
title={Eigen-Component Analysis: {A} Quantum Theory-Inspired Linear Model},
author={Chen, Rongzhou and Zhao, Yaping and Liu, Hanghang and Xu, Haohan and Ma, Shaohua and Lam, Edmund Y.},
booktitle={2025 IEEE International Symposium on Circuits and Systems (ISCAS)},
pages={},
year={2025},
publisher={IEEE},
doi={},
}结论
特征分量分析为分类和聚类任务引入了受量子启发的结构,同时保持学习表示的可检查性。它结合了 scikit-learn 风格的 API、PyTorch 后端和可视化工具,适合希望为表格数据或类似图像的数据构建可解释模型的研究人员和实践者。
从 PyPI 安装该包,或克隆 GitHub 仓库,然后从 Iris 这样的小型数据集或合成聚类问题开始。之后,检查变换后的数据、特征映射和特征特征,以理解模型正在学习什么。