
機械学習では、解釈が難しいブラックボックスとして振る舞う複雑なモデルに依存することがよくあります。Eigen-Component Analysis(ECA)は、量子理論から着想を得て、分類とクラスタリングのための解釈可能な線形モデルを構築します。本記事では、その中核となる考え方を紹介し、基本的な使い方を示し、eigen-analysis パッケージが提供する主要なパラメータを概説します。
Table of Contents
Eigen-Component Analysis とは?
Eigen-Component Analysis は、量子理論に着想を得たアイデアを応用し、分類とクラスタリングのための線形モデルを作成する手法です。従来の多くの前処理中心の手法とは異なり、ECA はデータの中心化や標準化を必須としないように設計されているため、ワークフローを単純にし、学習された表現をより調べやすくできます。
ECA の中心的な魅力は解釈可能性です。このモデルは、固有成分を通じて特徴量からクラスへの対応を明示し、研究者やデータサイエンティストが、なぜ予測やクラスタ割り当てが行われたのかを確認できるようにします。
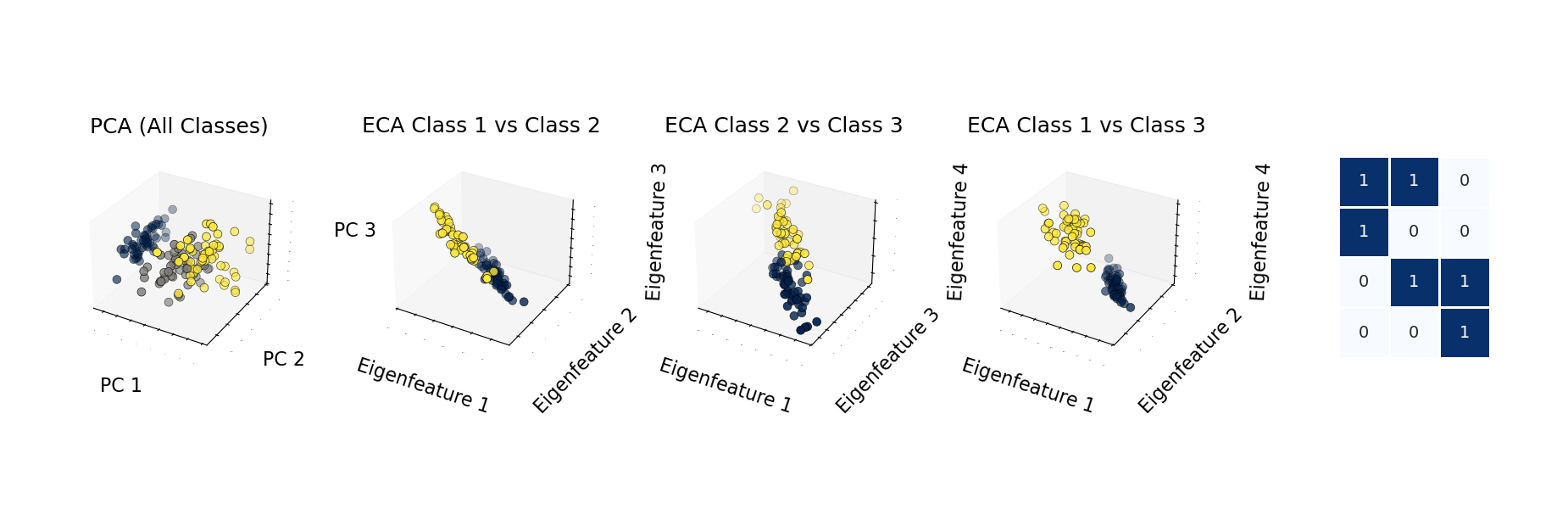
主な特徴と利点
ECA は理論的な構造と実用的な Python 実装を組み合わせています。
- scikit-learn 互換インターフェース:このパッケージはおなじみの scikit-learn Estimator API を実装しており、Python の機械学習エコシステムで作業しているユーザーにとって扱いやすくなっています。
- 教師あり・教師なしモード:ECA は、関連する実装である
ECAとUECAを通じて、教師あり分類と教師なしクラスタリングをサポートします。 - PyTorch バックエンド:実装は PyTorch 上に構築されており、互換性のある CUDA デバイスが利用可能な場合は GPU アクセラレーションを使用できます。
- 可視化ツール:このパッケージには、固有特徴量、特徴量マッピング、学習曲線、クラスタリングまたは分類結果のための描画ユーティリティが含まれています。
- 数学的基盤:ECA は反対称変換行列を使用し、量子論的な構造に着想を得たモデル表現を構築します。
ECA を始める
PyPI からパッケージをインストールします。実装を確認または変更したい場合は、ソースからインストールすることもできます。
# Installation from PyPI
pip install eigen-analysis
# Or from source
git clone https://github.com/lachlanchen/eca.git
cd eca
pip install .このパッケージは、NumPy、PyTorch、Matplotlib、Seaborn、scikit-learn、SciPy など、一般的なデータサイエンスライブラリに依存しています。ローカルインストールを確認するには、Python がパッケージをインポートできることを確認します。
python - <<'PY'
import eigen_analysis
print("eigen_analysis imported successfully")
PY分類に ECA を使う
次の例では、古典的な Iris データセットで ECA 分類器を学習します。
# iris_classification.py
import traceback
import numpy as np
from eigen_analysis import ECA
from eigen_analysis.visualization import visualize_clustering_results
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Load Iris dataset.
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split data.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=23,
stratify=y,
)
# Create and train ECA model.
eca = ECA(num_clusters=3, num_epochs=10000, learning_rate=0.001)
eca.fit(X_train, y_train)
# Make predictions.
y_pred = eca.predict(X_test)
# Evaluate accuracy.
accuracy = accuracy_score(y_test, y_pred)
print(f"Test accuracy: {accuracy:.4f}")
# Get transformed data.
X_transformed = eca.transform(X_test)
# Access model components.
P_matrix = eca.P_numpy_ # Eigenfeatures
L_matrix = eca.L_numpy_ # Feature-to-class mapping
# Visualize results.
visualize_clustering_results(
X_test,
y_test,
y_pred,
eca.loss_history_,
X_transformed,
eca.num_epochs,
eca.model_,
(eca.L_numpy_ > 0.5).astype(float),
eca.L_numpy_,
eca.P_numpy_,
"Iris",
output_dir="eca_classification_results_20250418",
)
except Exception:
traceback.print_exc()この例は、通常の教師あり学習ワークフローに従っています。データを読み込み、訓練セットとテストセットに分割し、モデルを適合させ、未知データのラベルを予測し、精度と学習された行列の両方を確認します。
UECA による教師なしクラスタリング
教師なし学習タスクでは、UECA 変種がクラスタリング機能を提供します。
# clustering_example.py
import traceback
import numpy as np
from eigen_analysis import UECA
from eigen_analysis.visualization import visualize_clustering_results
from sklearn.datasets import make_blobs
from sklearn.metrics import adjusted_rand_score
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Generate synthetic data.
X, y_true = make_blobs(n_samples=300, centers=3, random_state=42)
# Train UECA model. y_true is supplied here only for evaluation and visualization.
ueca = UECA(num_clusters=3, learning_rate=0.01, num_epochs=3000)
ueca.fit(X, y_true)
# Access clustering results.
clusters = ueca.labels_
remapped_clusters = ueca.remapped_labels_ # Optimal mapping to ground truth
# Evaluate clustering quality.
ari_score = adjusted_rand_score(y_true, clusters)
print(f"Adjusted Rand Index: {ari_score:.4f}")
# Visualize clustering results.
visualize_clustering_results(
X,
y_true,
remapped_clusters,
ueca.loss_history_,
ueca.transform(X),
ueca.num_epochs,
ueca.model_,
ueca.L_hard_numpy_,
ueca.L_numpy_,
ueca.P_numpy_,
"Custom Dataset",
output_dir="eca_clustering_results_20250418",
)
except Exception:
traceback.print_exc()クラスタリングでは、評価は利用可能なデータに依存します。正解ラベルが存在する場合、Adjusted Rand Index などの指標で一致度を定量化できます。ラベルが利用できない場合は、代わりにクラスタの安定性、変換後の表現、ドメイン固有のクラスタ品質を確認します。
高度な可視化とカスタマイズ
可視化ユーティリティでは、特徴量名とクラス名を使用して、プロットをより解釈しやすくできます。
# custom_visualization.py
visualize_clustering_results(
X,
y,
predictions,
loss_history,
projections,
num_epochs,
model,
L_hard,
L_soft,
P_matrix,
dataset_name="Iris",
feature_names=["Sepal Length", "Sepal Width", "Petal Length", "Petal Width"],
class_names=["Setosa", "Versicolor", "Virginica"],
output_dir="custom_visualization_20250418",
)MNIST のような画像データセットでは、専用の可視化関数によって、モデルが画像状の特徴空間をどのように解釈しているかを表示できます。
# mnist_example.py
import traceback
import numpy as np
from eigen_analysis import ECA
from eigen_analysis.visualization import visualize_mnist_eigenfeatures
from torchvision import datasets
# Set random seed for reproducibility.
np.random.seed(23)
try:
# Load MNIST.
mnist_train = datasets.MNIST("data", train=True, download=True)
X_train = mnist_train.data.reshape(-1, 784).float() / 255.0
y_train = mnist_train.targets
# Train ECA model.
eca = ECA(num_clusters=10, num_epochs=1000)
eca.fit(X_train, y_train)
# Visualize MNIST eigenfeatures.
visualize_mnist_eigenfeatures(eca.model_, output_dir="mnist_results_20250418")
except Exception:
traceback.print_exc()より大きなデータセットを扱う場合は、学習前に選択されたデバイスを確認し、収束の挙動に基づいて num_epochs と learning_rate を調整します。
print(f"Using device: {eca.device}")
print(f"Final loss: {eca.loss_history_[-1]:.6f}")モデルパラメータの調整
ECA の両変種は、特定のデータセットに合わせて調整できるパラメータを公開しています。
ECA モデル:教師あり分類
num_clusters:クラス数。learning_rate:オプティマイザの学習率。デフォルトは0.001です。num_epochs:学習エポック数。デフォルトは1000です。temp:シグモイドの温度パラメータ。デフォルトは10.0です。random_state:再現性のための乱数シード。device:使用するデバイス。例:cpuまたはcuda。
UECA モデル:教師なしクラスタリング
num_clusters:クラスタ数。learning_rate:オプティマイザの学習率。デフォルトは0.01です。num_epochs:学習エポック数。デフォルトは3000です。random_state:再現性のための乱数シード。device:使用するデバイス。例:cpuまたはcuda。
実用的なチューニング手順としては、まずデフォルト値から始め、損失曲線をプロットし、その後で学習率とエポック数を調整します。損失が振動または発散する場合は、学習率を下げます。学習終了時点でも損失がまだ減少している場合は、エポック数を増やします。
ECA の背後にある科学
ECA は、量子理論から着想を得て、分類とクラスタリングに対する数学的に構造化されたアプローチを作ります。その反対称変換行列は、学習された固有成分とクラスまたはクラスタ割り当てとの間に読み取り可能な関係を保ちながら、データを表現する方法を提供します。
この研究を発展させたい研究者向けに、プロジェクトは次のように引用できます。
@inproceedings{chen2025eigen,
title={Eigen-Component Analysis: {A} Quantum Theory-Inspired Linear Model},
author={Chen, Rongzhou and Zhao, Yaping and Liu, Hanghang and Xu, Haohan and Ma, Shaohua and Lam, Edmund Y.},
booktitle={2025 IEEE International Symposium on Circuits and Systems (ISCAS)},
pages={},
year={2025},
publisher={IEEE},
doi={},
}結論
Eigen-Component Analysis は、学習された表現を検査可能なまま保ちながら、量子に着想を得た構造を分類とクラスタリングのタスクにもたらします。scikit-learn 風の API、PyTorch バックエンド、可視化ユーティリティを組み合わせることで、表形式データや画像状データのための解釈可能なモデルを求める研究者や実務者にとって取り組みやすいものになっています。
PyPI からパッケージをインストールするか、GitHub リポジトリをクローンし、Iris のような小規模データセットや合成クラスタリング問題から始めてください。そこから、変換後のデータ、特徴量マッピング、固有特徴量を確認し、モデルが何を学習しているのかを理解できます。