
Table of Contents
用 Python 中的 Stan 理解高斯过程
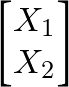
高斯过程是定义在函数上的分布。我们并不假设某个固定的参数形式,例如
y = a + bx而是为所有可能的函数定义一个先验,并让观测数据更新这个先验。核心思想很简单:任意有限个函数值都服从多元正态分布。
如果一个潜在函数写作
f(x) ~ GP(m(x), k(x, x'))那么对于观测输入点 x[1], ..., x[N],向量
[f(x[1]), ..., f(x[N])]服从多元正态分布,其均值向量由 m(x) 决定,协方差矩阵由核函数 k(x, x') 决定。
协方差核
协方差核控制了在看到数据之前哪些函数是合理的。一个常见选择是指数二次核,也称为平方指数核或径向基函数核:
k(x_i, x_j) = alpha^2 exp(-(x_i - x_j)^2 / (2 rho^2))这些参数有直观含义:
alpha控制函数的纵向尺度。rho控制长度尺度,也就是函数沿输入轴变化的快慢。sigma通常作为观测噪声单独加入。
对于有噪声的观测,模型为
y_i = f(x_i) + epsilon_i
epsilon_i ~ Normal(0, sigma)等价地,
y ~ MultiNormal(0, K + sigma^2 I)其中 K 是由核函数构造出的协方差矩阵。
为什么 Stan 适合高斯过程
Stan 在这里很有用,因为高斯过程回归是一个带有未知超参数的贝叶斯模型。我们通常不知道 alpha、rho 和 sigma 的正确取值,因此会为它们设置先验,并从数据中推断它们。
代价是计算成本。完整的高斯过程需要对一个 N x N 的协方差矩阵做 Cholesky 分解,计算复杂度大约按 O(N^3) 缩放。这对小型和中等规模示例没有问题,但对于大型数据集,应考虑稀疏或近似高斯过程方法。
Stan 模型
下面的 Stan 程序使用指数二次协方差函数。它会在对角线上加入一个很小的 jitter 项,以提高数值稳定性。
data {
int<lower=1> N;
array[N] real x;
vector[N] y;
}
transformed data {
real delta = 1e-9;
}
parameters {
real<lower=0> alpha;
real<lower=0> rho;
real<lower=0> sigma;
}
model {
matrix[N, N] K;
matrix[N, N] L_K;
alpha ~ normal(0, 1);
rho ~ inv_gamma(5, 5);
sigma ~ normal(0, 0.5);
K = gp_exp_quad_cov(x, alpha, rho);
for (n in 1:N) {
K[n, n] = K[n, n] + square(sigma) + delta;
}
L_K = cholesky_decompose(K);
y ~ multi_normal_cholesky(rep_vector(0, N), L_K);
}将其保存为 gp_regression.stan。
使用 CmdStanPy 的 Python 示例
Python 端只需要准备数据、编译 Stan 程序,并从后验中采样。请查看适用于你当前环境的 CmdStanPy 安装说明,因为安装细节可能会变化。一个本地健全性检查是:
python -c "import cmdstanpy; print(cmdstanpy.__version__)"一个最小可复现实例:
import numpy as np
import matplotlib.pyplot as plt
from cmdstanpy import CmdStanModel
rng = np.random.default_rng(20211202)
N = 40
x = np.linspace(-3, 3, N)
y_true = np.sin(x)
y = y_true + rng.normal(0, 0.15, size=N)
model = CmdStanModel(stan_file="gp_regression.stan")
fit = model.sample(
data={"N": N, "x": x.tolist(), "y": y.tolist()},
chains=4,
iter_warmup=1000,
iter_sampling=1000,
seed=20211202,
)
print(fit.summary().loc[["alpha", "rho", "sigma"]])
posterior = fit.draws_pd(vars=["alpha", "rho", "sigma"])
print(posterior.describe())
plt.scatter(x, y, label="observed", color="black")
plt.plot(x, y_true, label="true function", color="tab:blue")
plt.legend()
plt.show()这个模型会估计协方差超参数,但它还不会在新的输入点上生成预测。若要预测,可以把测试输入加入 Stan 的 data block,并使用条件多元正态公式;或者用采样得到的超参数在 Python 中生成后验预测。
后验预测公式
设 x_train 为观测输入,x_test 为新的输入。定义:
K = k(x_train, x_train) + sigma^2 I
K_star = k(x_train, x_test)
K_test = k(x_test, x_test)测试点处潜在函数的条件分布为
f_test | y ~ Normal(K_star^T K^{-1} y,
K_test - K_star^T K^{-1} K_star)实现时,避免直接计算 K^{-1}。应改用 Cholesky 因子和三角求解。这既更快,也更具数值稳定性。
实用检查
对于用 Stan 拟合的高斯过程,我通常会检查以下几点:
- 对
alpha、rho和sigma来说,Rhat应接近1.0。 - 有效样本量不应极小。
- 后验预测应在与学到的
rho一致的尺度上保持平滑。 sigma相对于观测噪声应是合理的。- 如果采样器报告发散,应检查先验并重新缩放输入数据。
输入缩放很重要。一个适用于 x 在 [-3, 3] 中的长度尺度先验,可能并不适合 x 在 [0, 100000] 中的情况。稳定的工作流程是先对输入做标准化或重新缩放,拟合模型,然后在变换后的尺度上解释长度尺度。
总结
高斯过程通过协方差核定义函数上的先验。Stan 让我们能够推断核函数超参数,而不是手动固定它们。基本实现很紧凑:构建协方差矩阵,在对角线上加入观测噪声和 jitter,使用 Cholesky 分解,然后对超参数采样。对于小型数据集,这会得到一个清晰且灵活的贝叶斯回归模型;对于大型数据集,同样的思想仍然有用,但近似方法会变得必要。