
Table of Contents
Python の Stan でガウス過程を理解する
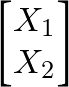
ガウス過程は、関数上の分布である。たとえば
y = a + bxのような固定されたパラメトリックな形を仮定する代わりに、もっともらしいすべての関数に対して事前分布を定義し、観測データによってその事前分布を更新する。中心となる考え方は単純で、関数値の任意の有限集合が多変量正規分布に従う、というものである。
潜在関数を
f(x) ~ GP(m(x), k(x, x'))と書くなら、観測された入力点 x[1], ..., x[N] に対して、ベクトル
[f(x[1]), ..., f(x[N])]は、m(x) によって決まる平均ベクトルと、カーネル k(x, x') によって決まる共分散行列を持つ多変量正規分布に従う。
共分散カーネル
共分散カーネルは、データを見る前にどのような関数がもっともらしいかを制御する。よく使われる選択肢は指数二次カーネルであり、二乗指数カーネルまたは動径基底関数カーネルとも呼ばれる。
k(x_i, x_j) = alpha^2 exp(-(x_i - x_j)^2 / (2 rho^2))各パラメータの役割は直感的である。
alphaは関数の縦方向のスケールを制御する。rhoは長さスケール、つまり入力軸に沿って関数がどれだけ速く変化できるかを制御する。sigmaは通常、観測ノイズとして別に加えられる。
ノイズを含む観測では、モデルは
y_i = f(x_i) + epsilon_i
epsilon_i ~ Normal(0, sigma)となる。同値に、
y ~ MultiNormal(0, K + sigma^2 I)と書ける。ここで K はカーネルから構成される共分散行列である。
Stan がガウス過程に向いている理由
ここで Stan が有用なのは、ガウス過程回帰が未知のハイパーパラメータを持つベイズモデルだからである。通常、alpha、rho、sigma の正しい値はわからないため、それらに事前分布を置き、データから推論する。
その代償は計算コストである。完全なガウス過程では N x N の共分散行列のコレスキー分解が必要であり、計算量はおおよそ O(N^3) でスケールする。小規模から中規模の例では問題ないが、大規模データセットではスパースまたは近似的なガウス過程手法を検討すべきである。
Stan モデル
次の Stan プログラムは指数二次共分散関数を使う。数値的安定性のため、対角成分に小さなジッター項を加えている。
data {
int<lower=1> N;
array[N] real x;
vector[N] y;
}
transformed data {
real delta = 1e-9;
}
parameters {
real<lower=0> alpha;
real<lower=0> rho;
real<lower=0> sigma;
}
model {
matrix[N, N] K;
matrix[N, N] L_K;
alpha ~ normal(0, 1);
rho ~ inv_gamma(5, 5);
sigma ~ normal(0, 0.5);
K = gp_exp_quad_cov(x, alpha, rho);
for (n in 1:N) {
K[n, n] = K[n, n] + square(sigma) + delta;
}
L_K = cholesky_decompose(K);
y ~ multi_normal_cholesky(rep_vector(0, N), L_K);
}これを gp_regression.stan として保存する。
CmdStanPy を使った Python の例
Python 側で必要なのは、データを用意し、Stan プログラムをコンパイルし、事後分布からサンプリングすることだけである。インストールの詳細は変わる可能性があるため、現在の CmdStanPy のインストール手順を自分の環境に合わせて確認する。ローカルでの簡単な健全性チェックは次の通りである。
python -c "import cmdstanpy; print(cmdstanpy.__version__)"最小限の再現可能な例は次の通りである。
import numpy as np
import matplotlib.pyplot as plt
from cmdstanpy import CmdStanModel
rng = np.random.default_rng(20211202)
N = 40
x = np.linspace(-3, 3, N)
y_true = np.sin(x)
y = y_true + rng.normal(0, 0.15, size=N)
model = CmdStanModel(stan_file="gp_regression.stan")
fit = model.sample(
data={"N": N, "x": x.tolist(), "y": y.tolist()},
chains=4,
iter_warmup=1000,
iter_sampling=1000,
seed=20211202,
)
print(fit.summary().loc[["alpha", "rho", "sigma"]])
posterior = fit.draws_pd(vars=["alpha", "rho", "sigma"])
print(posterior.describe())
plt.scatter(x, y, label="observed", color="black")
plt.plot(x, y_true, label="true function", color="tab:blue")
plt.legend()
plt.show()このモデルは共分散のハイパーパラメータを推定するが、まだ新しい入力点での予測は生成しない。予測を行うには、Stan の data ブロックにテスト入力を追加して条件付き多変量正規分布の公式を使うか、サンプリングされたハイパーパラメータを用いて Python 側で事後予測を生成する。
事後予測の公式
x_train を観測入力、x_test を新しい入力とする。次のように定義する。
K = k(x_train, x_train) + sigma^2 I
K_star = k(x_train, x_test)
K_test = k(x_test, x_test)テスト点における潜在関数の条件付き分布は
f_test | y ~ Normal(K_star^T K^{-1} y,
K_test - K_star^T K^{-1} K_star)である。実装では K^{-1} を直接計算するのは避ける。代わりにコレスキー因子と三角行列の求解を使う。こちらの方が高速で、数値的にも安定している。
実践的な確認項目
Stan でフィットしたガウス過程について、私は通常次の点を確認する。
alpha、rho、sigmaのRhatは1.0に近いべきである。- 有効サンプルサイズが極端に小さくないこと。
- 事後予測が、学習された
rhoと整合するスケールで滑らかであること。 sigmaが観測ノイズに対してもっともらしいこと。- サンプラーが発散を報告する場合は、事前分布を確認し、入力データをリスケールすること。
入力のスケーリングは重要である。[-3, 3] の x ではうまく働く長さスケールの事前分布が、[0, 100000] の x では不適切かもしれない。安定したワークフローは、まず入力を標準化またはリスケールし、モデルをフィットしてから、その変換後のスケール上で長さスケールを解釈することである。
まとめ
ガウス過程は、共分散カーネルを通じて関数上の事前分布を定義する。Stan を使うと、カーネルのハイパーパラメータを手で固定する代わりに推論できる。基本的な実装は簡潔である。共分散行列を構成し、観測ノイズとジッターを対角成分に加え、コレスキー分解を使い、ハイパーパラメータをサンプリングする。小規模データセットでは、これは明快で柔軟なベイズ回帰モデルになる。大規模データセットでは同じ考え方は有用なままだが、近似手法が必要になる。