
以一个疾病诊断系统为例,这些评估术语可以用混淆矩阵中的比率来描述。
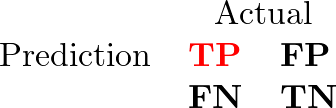
四个单元格分别是:
- TP:真正例,实际患病且被预测为患病的人。
- FP:假正例,健康但被预测为患病的人。
- FN:假负例,实际患病但被预测为健康的人。
- TN:真负例,健康且被预测为健康的人。
Table of Contents
准确率
准确率是在所有人中被正确预测的比例。
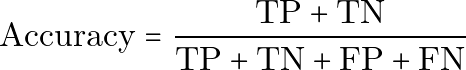
用纯文本表示:
Accuracy = (TP + TN) / (TP + TN + FP + FN)准确率很容易理解,但在类别不平衡时可能会产生误导。例如,如果只有 1% 的人患有某种疾病,一个把所有人都预测为健康的模型仍然可以达到 99% 的准确率,却找不到任何真正的病例。
精确率
精确率是在所有被预测为患病的人中,真正患病者所占的比例。
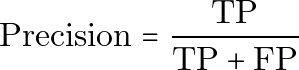
用纯文本表示:
Precision = TP / (TP + FP)高精确率意味着当系统预测患病时,这个预测通常是正确的。当假正例的代价很高时,精确率尤其重要。
召回率、灵敏度和真正例率
召回率,也称为灵敏度或真正例率,衡量模型找出了多少实际为正的样本。
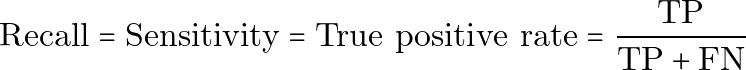
用纯文本表示:
Recall = Sensitivity = True positive rate = TP / (TP + FN)高召回率意味着系统漏掉的实际患病者更少。当假负例很危险时,召回率尤其重要。
特异度
特异度,也称为真负例率,衡量有多少健康人被正确识别为健康。
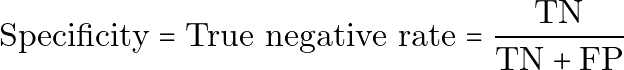
用纯文本表示:
Specificity = True negative rate = TN / (TN + FP)高特异度意味着系统会避免把健康人错误地标记为患病。
F1 分数
F1 分数把精确率和召回率合并为一个指标。它是精确率和召回率的调和平均数。
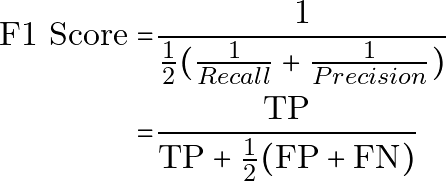
用纯文本表示:
F1 Score = 1 / ((1 / 2) * ((1 / Recall) + (1 / Precision)))
= TP / (TP + (1 / 2) * (FP + FN))等价地:
F1 Score = 2 * Precision * Recall / (Precision + Recall)当假正例和假负例都重要时,尤其是在类别不平衡的情况下,F1 分数很有用。它不直接包含真负例,因此应结合混淆矩阵以及每种错误的实际代价一起解读。