
病気を診断するシステムを考えると、これらの評価指標は混同行列の割合として説明できます。
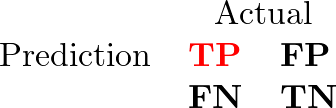
4つのセルは次のとおりです。
- TP: 真陽性。実際に病気があり、病気があると予測された人。
- FP: 偽陽性。健康であるにもかかわらず、病気があると予測された人。
- FN: 偽陰性。実際に病気があるにもかかわらず、健康だと予測された人。
- TN: 真陰性。健康であり、健康だと予測された人。
Table of Contents
Accuracy
Accuracy(正解率)は、すべての人のうち正しく予測された人の割合です。
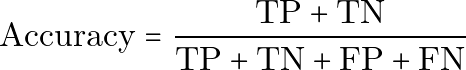
プレーンテキストでは次のようになります。
Accuracy = (TP + TN) / (TP + TN + FP + FN)Accuracy は理解しやすい指標ですが、クラスが不均衡な場合には誤解を招くことがあります。たとえば、病気を持つ人が全体の 1% しかいない場合、全員を健康だと予測するモデルでも 99% の Accuracy に達することができますが、実際の症例は1つも見つけられません。
Precision
Precision(適合率)は、病気があると予測されたすべての人のうち、本当に病気を持っている人の割合です。
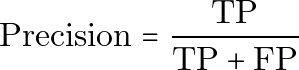
プレーンテキストでは次のようになります。
Precision = TP / (TP + FP)Precision が高いということは、システムが病気だと予測したとき、その予測が通常正しいことを意味します。偽陽性のコストが高い場合には、Precision が特に重要です。
Recall、Sensitivity、True Positive Rate
Recall(再現率)は、sensitivity(感度)または true positive rate(真陽性率)とも呼ばれ、実際の陽性例のうちモデルがどれだけ見つけられたかを測ります。
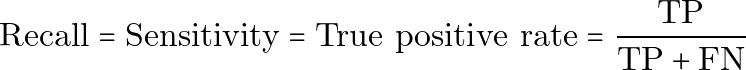
プレーンテキストでは次のようになります。
Recall = Sensitivity = True positive rate = TP / (TP + FN)Recall が高いということは、実際に病気を持っている人を見逃す数が少ないことを意味します。偽陰性が危険な場合には、Recall が特に重要です。
Specificity
Specificity(特異度)は、true negative rate(真陰性率)とも呼ばれ、健康な人がどれだけ正しく健康だと識別されたかを測ります。
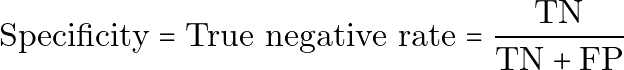
プレーンテキストでは次のようになります。
Specificity = True negative rate = TN / (TN + FP)Specificity が高いということは、健康な人を誤って病気だとラベル付けすることを避けられていることを意味します。
F1 Score
F1 score は、Precision と Recall を1つの指標にまとめたものです。Precision と Recall の調和平均です。
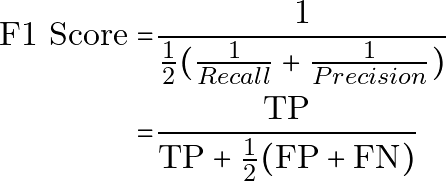
プレーンテキストでは次のようになります。
F1 Score = 1 / ((1 / 2) * ((1 / Recall) + (1 / Precision)))
= TP / (TP + (1 / 2) * (FP + FN))同等に、次のようにも表せます。
F1 Score = 2 * Precision * Recall / (Precision + Recall)F1 score は、偽陽性と偽陰性の両方が重要な場合、特にクラスが不均衡な場合に有用です。真陰性は直接含まれていないため、混同行列と各種類の誤りが持つ実際のコストとあわせて解釈する必要があります。