
Table of Contents
Introduction
For quite some time, I had wanted to read and implement the Transformer paper. After going through several well-illustrated posts, such as Transformers from Scratch and The Illustrated Transformer, the concepts still felt abstract to me because I had not run the code myself. Many people mentioned that a full implementation would be tedious. However, with the help of ChatGPT, I was able to build a minimum viable product that made these ideas more tangible. As I watched the training epoch outputs and generated text, the previously abstract concepts began to take a more concrete form.
In this post, we will create a small Transformer-style language model in PyTorch with the help of OpenAI’s ChatGPT. We will build a toy dataset, tokenize it, create a vocabulary, encode the input, and train a model to predict the next token. The model includes token embeddings, positional encoding, multi-head self-attention, a position-wise feed-forward network, residual connections, and layer normalization.
This is intentionally a small educational example. It is not meant to produce a useful language model, but it is enough to make the main moving parts of a Transformer easier to inspect.
1. Prepare the Dataset
First, create a tiny dataset with three sentences:
sentences = [
"The quick brown fox jumped over the lazy dog.",
"Advancements in AI have transformed the way we interact with technology.",
"Yesterday, the stock market experienced a significant decline due to geopolitical tensions."
]2. Tokenize the Dataset
For this minimal example, we tokenize by splitting each sentence on whitespace:
tokenized_sentences = [sentence.split() for sentence in sentences]This is simple, but it is also limited. Punctuation remains attached to words, so dog. and dog would be treated as different tokens. In a real project, use a tokenizer appropriate for the model and corpus.
3. Create the Vocabulary
Next, create a vocabulary from the tokenized sentences. We include special tokens for padding, the beginning of a sentence, and the end of a sentence.
word2idx = {"[PAD]": 0, "[CLS]": 1, "[SEP]": 2}
for sentence in tokenized_sentences:
for token in sentence:
if token not in word2idx:
word2idx[token] = len(word2idx)
idx2word = {idx: word for word, idx in word2idx.items()}4. Encode and Pad the Dataset
Now convert each token into an integer ID, add the special tokens, and pad all sequences to the same length.
max_seq_len = max(len(sentence) for sentence in tokenized_sentences) + 2
encoded_sentences = []
for sentence in tokenized_sentences:
encoded_sentence = [word2idx["[CLS]"]] + [word2idx[word] for word in sentence] + [word2idx["[SEP]"]]
encoded_sentence += [word2idx["[PAD]"]] * (max_seq_len - len(encoded_sentence))
encoded_sentences.append(encoded_sentence)The + 2 accounts for the [CLS] and [SEP] tokens. Without that, the longest sequence would not have enough room after adding the special tokens.
5. Define the Transformer Model
Here is a compact PyTorch implementation of the main components.
import torch
import torch.nn as nn
import torch.optim as optim
class PositionalEncoding(nn.Module):
def __init__(self, d_model):
super(PositionalEncoding, self).__init__()
self.d_model = d_model
def forward(self, x):
seq_len = x.size(1)
pe = torch.zeros(seq_len, self.d_model)
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, self.d_model, 2).float()
* (-torch.log(torch.tensor(10000.0)) / self.d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).to(x.device)
x = x + pe
return x
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, nhead):
super(MultiHeadAttention, self).__init__()
assert d_model % nhead == 0
self.nhead = nhead
self.head_dim = d_model // nhead
self.qkv_linear = nn.Linear(d_model, d_model * 3)
self.fc = nn.Linear(d_model, d_model)
self.scale = self.head_dim ** -0.5
def forward(self, x):
batch_size, seq_len, _ = x.size()
qkv = self.qkv_linear(x)
qkv = qkv.view(batch_size, seq_len, self.nhead, 3 * self.head_dim)
qkv = qkv.transpose(1, 2)
q, k, v = qkv.chunk(3, dim=-1)
attn_scores = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_len, -1)
attn_output = self.fc(attn_output)
return attn_output
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, dim_feedforward):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(d_model, dim_feedforward)
self.fc2 = nn.Linear(dim_feedforward, d_model)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward):
super(TransformerBlock, self).__init__()
self.mha = MultiHeadAttention(d_model, nhead)
self.ffn = FeedForwardNetwork(d_model, dim_feedforward)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
attn_output = self.mha(x)
x = self.norm1(x + self.dropout(attn_output))
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers, dim_feedforward):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(d_model, nhead, dim_feedforward) for _ in range(num_layers)]
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embedding(x)
x = self.pos_encoding(x)
for block in self.transformer_blocks:
x = block(x)
x = self.fc(x)
return xThe attention block projects each token representation into query, key, and value vectors. The query-key dot product estimates how strongly each token should attend to each other token. The value vectors are then combined according to those attention weights.
6. Train the Model
Instantiate the model, define the loss function and optimizer, then train for a few epochs.
vocab_size = len(word2idx)
d_model = 8
nhead = 2
num_layers = 1
dim_feedforward = 16
model = TransformerModel(vocab_size, d_model, nhead, num_layers, dim_feedforward)
criterion = nn.CrossEntropyLoss(ignore_index=word2idx["[PAD]"])
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_data = torch.tensor(encoded_sentences[:-1], dtype=torch.long)
target_data = torch.tensor(encoded_sentences[1:], dtype=torch.long)
num_epochs = 200
for epoch in range(num_epochs):
optimizer.zero_grad()
output = model(input_data)
loss = criterion(output.view(-1, vocab_size), target_data.view(-1))
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")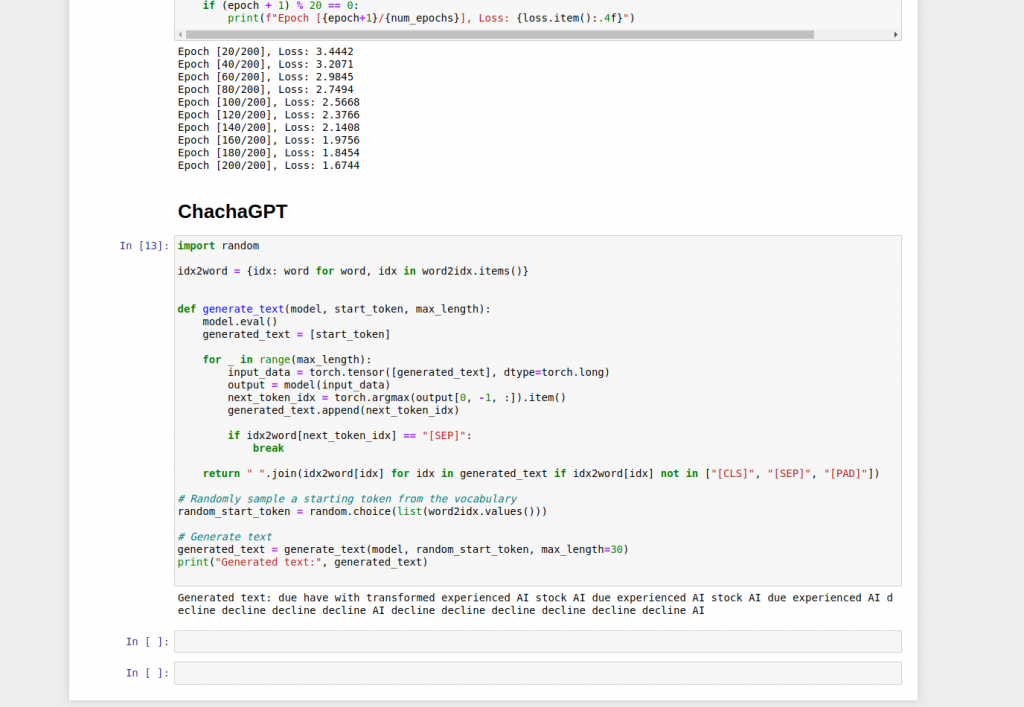
This toy training setup uses each sentence to predict the next encoded sentence, so it is only a rough demonstration of tensor shapes, optimization, and the model structure. For a more conventional next-token language-modeling setup, construct input-target pairs by shifting the same sequence by one token:
all_sequences = torch.tensor(encoded_sentences, dtype=torch.long)
input_data = all_sequences[:, :-1]
target_data = all_sequences[:, 1:]Then train with the same model output and cross-entropy loss pattern.
Conclusion
In this post, we created a simple Transformer-style model in PyTorch with the help of OpenAI’s ChatGPT. The exercise covered a minimal dataset, whitespace tokenization, vocabulary construction, positional encoding, multi-head attention, feed-forward layers, residual connections, and a short training loop.
The key benefit of this kind of MVP is not performance. It is visibility. Running a small model makes the abstract components of the Transformer easier to inspect, debug, and connect to the diagrams in the original explanations.
To see the prompts I used and the resulting code, visit my GitHub repository: BuildChachaGPTWithChatGPT.