
Table of Contents
はじめに
かなり以前から、Transformerの論文を読み、実装してみたいと思っていました。Transformers from Scratch や The Illustrated Transformer のような図解の優れた記事をいくつか読んでも、自分でコードを動かしていなかったため、概念はまだ抽象的に感じられました。完全な実装は面倒だと述べている人も多くいました。しかしChatGPTの助けを借りることで、これらの考え方をより具体的に感じられる最小限の実用例を作ることができました。学習エポックの出力や生成されたテキストを見ているうちに、それまで抽象的だった概念が、より具体的な形を取り始めました。
この記事では、OpenAIのChatGPTの助けを借りながら、PyTorchで小さなTransformer風の言語モデルを作ります。おもちゃのデータセットを用意し、トークン化し、語彙を作成し、入力をエンコードし、次のトークンを予測するモデルを学習します。このモデルには、トークン埋め込み、位置エンコーディング、マルチヘッド自己注意、位置ごとのフィードフォワードネットワーク、残差接続、レイヤー正規化が含まれます。
これは意図的に小さくした教育用の例です。実用的な言語モデルを作ることを目的にはしていませんが、Transformerの主要な構成要素を観察しやすくするには十分です。
1. データセットを準備する
まず、3つの文からなる小さなデータセットを作成します。
sentences = [
"The quick brown fox jumped over the lazy dog.",
"Advancements in AI have transformed the way we interact with technology.",
"Yesterday, the stock market experienced a significant decline due to geopolitical tensions."
]2. データセットをトークン化する
この最小限の例では、各文を空白で分割してトークン化します。
tokenized_sentences = [sentence.split() for sentence in sentences]これは単純ですが、制限もあります。句読点が単語に付いたままになるため、dog. と dog は異なるトークンとして扱われます。実際のプロジェクトでは、モデルとコーパスに適したトークナイザーを使ってください。
3. 語彙を作成する
次に、トークン化された文から語彙を作成します。パディング、文の開始、文の終了を表す特殊トークンも含めます。
word2idx = {"[PAD]": 0, "[CLS]": 1, "[SEP]": 2}
for sentence in tokenized_sentences:
for token in sentence:
if token not in word2idx:
word2idx[token] = len(word2idx)
idx2word = {idx: word for word, idx in word2idx.items()}4. データセットをエンコードしてパディングする
次に、各トークンを整数IDに変換し、特殊トークンを追加し、すべての系列を同じ長さにパディングします。
max_seq_len = max(len(sentence) for sentence in tokenized_sentences) + 2
encoded_sentences = []
for sentence in tokenized_sentences:
encoded_sentence = [word2idx["[CLS]"]] + [word2idx[word] for word in sentence] + [word2idx["[SEP]"]]
encoded_sentence += [word2idx["[PAD]"]] * (max_seq_len - len(encoded_sentence))
encoded_sentences.append(encoded_sentence)+ 2 は [CLS] と [SEP] トークンの分を考慮するためのものです。これがないと、特殊トークンを追加した後に最長の系列を収める十分な長さがありません。
5. Transformerモデルを定義する
以下は、主要な構成要素をコンパクトにまとめたPyTorch実装です。
import torch
import torch.nn as nn
import torch.optim as optim
class PositionalEncoding(nn.Module):
def __init__(self, d_model):
super(PositionalEncoding, self).__init__()
self.d_model = d_model
def forward(self, x):
seq_len = x.size(1)
pe = torch.zeros(seq_len, self.d_model)
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, self.d_model, 2).float()
* (-torch.log(torch.tensor(10000.0)) / self.d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).to(x.device)
x = x + pe
return x
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, nhead):
super(MultiHeadAttention, self).__init__()
assert d_model % nhead == 0
self.nhead = nhead
self.head_dim = d_model // nhead
self.qkv_linear = nn.Linear(d_model, d_model * 3)
self.fc = nn.Linear(d_model, d_model)
self.scale = self.head_dim ** -0.5
def forward(self, x):
batch_size, seq_len, _ = x.size()
qkv = self.qkv_linear(x)
qkv = qkv.view(batch_size, seq_len, self.nhead, 3 * self.head_dim)
qkv = qkv.transpose(1, 2)
q, k, v = qkv.chunk(3, dim=-1)
attn_scores = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_output = torch.matmul(attn_weights, v)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_len, -1)
attn_output = self.fc(attn_output)
return attn_output
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, dim_feedforward):
super(FeedForwardNetwork, self).__init__()
self.fc1 = nn.Linear(d_model, dim_feedforward)
self.fc2 = nn.Linear(dim_feedforward, d_model)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward):
super(TransformerBlock, self).__init__()
self.mha = MultiHeadAttention(d_model, nhead)
self.ffn = FeedForwardNetwork(d_model, dim_feedforward)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
attn_output = self.mha(x)
x = self.norm1(x + self.dropout(attn_output))
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_layers, dim_feedforward):
super(TransformerModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(d_model, nhead, dim_feedforward) for _ in range(num_layers)]
)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, x):
x = self.embedding(x)
x = self.pos_encoding(x)
for block in self.transformer_blocks:
x = block(x)
x = self.fc(x)
return x注意ブロックは、各トークン表現をクエリ、キー、バリューのベクトルに射影します。クエリとキーのドット積によって、各トークンが他の各トークンにどの程度強く注意を向けるべきかを推定します。その後、その注意重みに従ってバリューベクトルが結合されます。
6. モデルを学習する
モデルをインスタンス化し、損失関数とオプティマイザーを定義してから、数エポック学習します。
vocab_size = len(word2idx)
d_model = 8
nhead = 2
num_layers = 1
dim_feedforward = 16
model = TransformerModel(vocab_size, d_model, nhead, num_layers, dim_feedforward)
criterion = nn.CrossEntropyLoss(ignore_index=word2idx["[PAD]"])
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_data = torch.tensor(encoded_sentences[:-1], dtype=torch.long)
target_data = torch.tensor(encoded_sentences[1:], dtype=torch.long)
num_epochs = 200
for epoch in range(num_epochs):
optimizer.zero_grad()
output = model(input_data)
loss = criterion(output.view(-1, vocab_size), target_data.view(-1))
loss.backward()
optimizer.step()
if (epoch + 1) % 20 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}")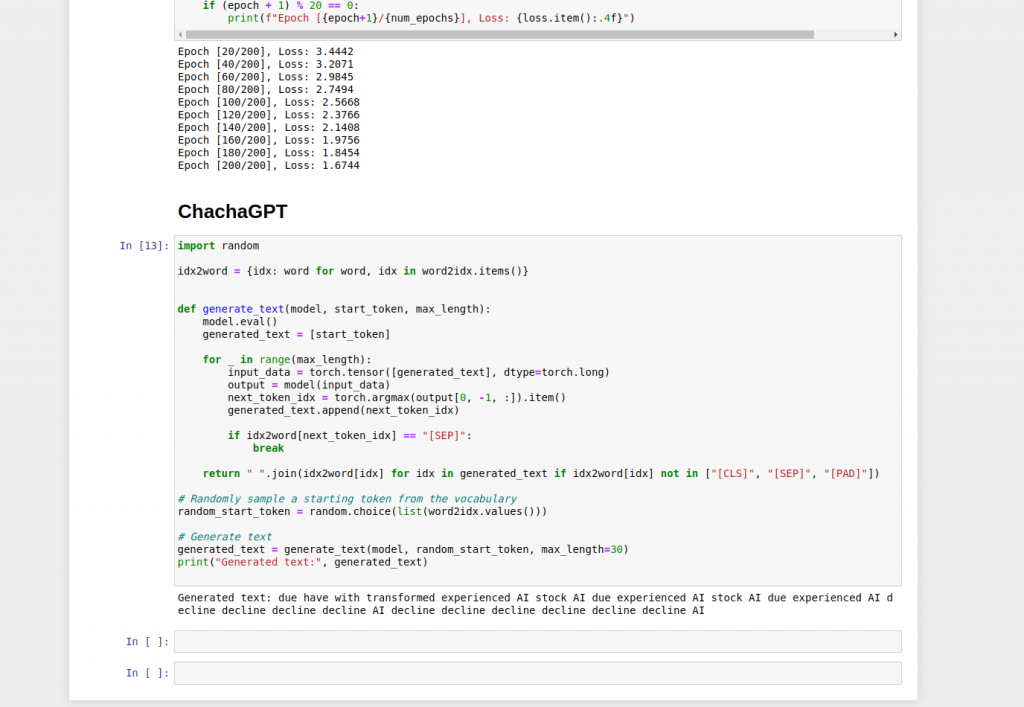
このおもちゃの学習設定では、各文を使って次のエンコード済み文を予測しているため、テンソル形状、最適化、モデル構造を示すための大まかなデモにすぎません。より一般的な次トークン言語モデリングの設定では、同じ系列を1トークンずらして入力とターゲットのペアを作ります。
all_sequences = torch.tensor(encoded_sentences, dtype=torch.long)
input_data = all_sequences[:, :-1]
target_data = all_sequences[:, 1:]その後、同じモデル出力とクロスエントロピー損失のパターンで学習します。
まとめ
この記事では、OpenAIのChatGPTの助けを借りながら、PyTorchでシンプルなTransformer風モデルを作成しました。この演習では、最小限のデータセット、空白によるトークン化、語彙構築、位置エンコーディング、マルチヘッド注意、フィードフォワード層、残差接続、短い学習ループを扱いました。
このようなMVPの主な利点は性能ではありません。可視性です。小さなモデルを動かすことで、Transformerの抽象的な構成要素を観察し、デバッグし、元の解説にある図と結びつけやすくなります。
私が使ったプロンプトと、その結果得られたコードを見るには、GitHubリポジトリ BuildChachaGPTWithChatGPT を参照してください。