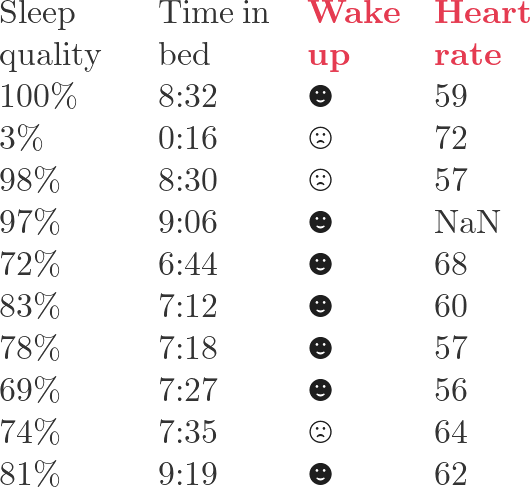
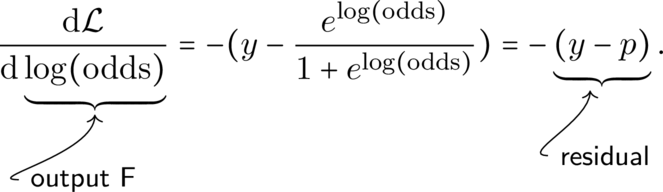在整个教程中,我们会使用这个简单的数据集
Boosting 是一种加性建模策略。我们不是一次性训练一个复杂模型,而是按顺序训练许多简单模型。每个新模型都试图修正当前集成模型仍然预测错误的部分。
把第 m 步之后的预测写成
\[F_m(x) = F_{m-1}(x) + eta f_m(x),\]
其中 F_{m-1} 是当前模型,f_m 是新的弱学习器,eta 是学习率。在树提升中,f_m 通常是一棵回归树。关键思想是,这棵树并不直接学习原始目标;它学习的是当前预测应该移动的方向。
对于平方误差回归,这个方向很容易看出:
\[L(y, F(x)) = frac{1}{2}(y - F(x))^2,\]
因此负梯度是
\[-frac{partial L}{partial F} = y - F(x).\]
这正是残差。这也是为什么可以把梯度提升介绍为“让下一棵树拟合残差”。对于其他损失函数,同样的思想仍然成立,只是残差变成了由梯度推导出的伪残差。
梯度提升的损失函数可以写成
\[mathcal{L}^{(t)} = sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right) + Omega(f_t).\]
这里 hat{y}_i^{(t-1)} 是加入新树之前的预测,f_t(x_i) 是新树给出的更新,Omega(f_t) 是正则化项。为了建立直觉,先忽略正则化:
\[mathcal{L}^{(t)} approx sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right).\]
对于平方误差,
\[l(y_i, hat{y}_i) = frac{1}{2}(y_i - hat{y}_i)^2.\]
它对当前预测的导数是
\[frac{partial l}{partial hat{y}_i} = hat{y}_i - y_i.\]
因此负梯度是
\[y_i - hat{y}_i,\]
这恰好就是残差。所以一次回归 boosting 迭代可以写成:
使用当前集成模型进行预测。
计算残差或负梯度。
训练一棵新树去拟合这些残差。
把这棵树加入集成模型,通常还会乘上一个学习率。
这解释了从普通残差拟合到梯度提升之间的桥梁:残差是负梯度的一个特殊情况。
说明: 为了避免符号过重,下面有时会省略求和符号 sum。这里的推导针对二分类。
对于一个二分类问题,把赔率定义为
\[text{odds} = frac{text{win}}{text{lose}}.\]
概率为
\[p = frac{text{win}}{text{win}+text{lose}}.\]
通过简单代数变形,
\[p = frac{text{odds}}{1 + text{odds}}
= frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}.\]
这就是作用在对数赔率上的 logistic sigmoid。令
\[F_m = log(text{odds}) = F_{m-1} + gamma.\]
则
\[p = frac{e^{F_m}}{1 + e^{F_m}}.\]
使用二元交叉熵作为损失函数:
\[begin{aligned}
mathcal{L}(y, F_{m-1} + gamma)
&= -left[ylog(p) + (1-y)log(1-p)right] \
&= -left[yleft(log(p)-log(1-p)right) + log(1-p)right] \
&= -left[ylogfrac{p}{1-p} - log(1+text{odds})right] \
&= -left[ylog(text{odds}) - logleft(1+e^{log(text{odds})}right)right].
end{aligned}\]
我们希望找到使损失最小的 gamma:
\[operatorname*{arg,min}_{gamma}; mathcal{L}.\]
我们可以直接处理损失函数并求解
\[frac{partial mathcal{L}}{partial gamma} = 0,\]
但这样会变得繁琐。二阶泰勒近似可以给出更清晰的更新方式。在当前得分 F_{m-1} 附近,
\[mathcal{L}(y, F_{m-1}+gamma)
approx
mathcal{L}(y, F_{m-1})
+ ggamma
+ frac{1}{2}hgamma^2,\]
其中
\[g = frac{partial mathcal{L}}{partial F},
qquad
h = frac{partial^2 mathcal{L}}{partial F^2}.\]
令它对 gamma 的导数为零:
\[frac{partial}{partial gamma}left(mathcal{L}(y, F_{m-1}) + ggamma + frac{1}{2}hgamma^2right) = 0.\]
得到
\[g + hgamma = 0,\]
所以最优的局部更新为
\[gamma = -frac{g}{h}.\]
对于二元交叉熵,它对 F = log(text{odds}) 的一阶导数为
\[frac{partial mathcal{L}}{partial log(text{odds})}
= -left(y - frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}right)
= p-y.\]
配合一些示意:
mathcal{L} 对 log(text{odds}) 的二阶导数是
\[begin{aligned}
frac{partial^2 mathcal{L}}{partial log(text{odds})^2}
&= frac{partial}{partial log(text{odds})}
frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}} \
&= frac{e^{log(text{odds})}(1 + e^{log(text{odds})}) - e^{2log(text{odds})}}{(1 + e^{log(text{odds})})^2} \
&= frac{1}{1 + e^{log(text{odds})}}
frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}} \
&= p(1-p).
end{aligned}\]
因此,对于一个观测值,
\[gamma = -frac{p-y}{p(1-p)} = frac{y-p}{p(1-p)}.\]
对于包含多个观测值的叶子节点,Newton 风格的更新会聚合梯度和 Hessian:
\[gamma_j = -frac{sum_{i in I_j} g_i}{sum_{i in I_j} h_i}.\]
这就是从梯度提升分类到 XGBoost 的实用桥梁。
XGBoost 保留了加性树模型,但把目标函数写得更明确,并加入正则化。在第 t 轮 boosting 中,它最小化
\[mathcal{L}^{(t)} = sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right) + Omega(f_t),\]
其中树的正则化通常写作
\[Omega(f) = gamma T + frac{1}{2}lambdasum_{j=1}^{T} w_j^2.\]
这里 T 是叶子数量,w_j 是第 j 个叶子的分数,gamma 惩罚新增叶子,lambda 是作用在叶子权重上的 L2 正则化。
使用二阶泰勒近似,
\[mathcal{L}^{(t)} approx
sum_{i=1}^{n}left[g_i f_t(x_i) + frac{1}{2}h_i f_t(x_i)^2right] + Omega(f_t),\]
其中
\[g_i = frac{partial l(y_i, hat{y}_i^{(t-1)})}{partial hat{y}_i^{(t-1)}},
qquad
h_i = frac{partial^2 l(y_i, hat{y}_i^{(t-1)})}{partial (hat{y}_i^{(t-1)})^2}.\]
对于一个固定的树结构,每个样本都会落入某个叶子。令 I_j 表示落入第 j 个叶子的样本集合,并定义
\[G_j = sum_{i in I_j} g_i,
qquad
H_j = sum_{i in I_j} h_i.\]
第 j 个叶子的目标函数变为
\[G_j w_j + frac{1}{2}(H_j + lambda)w_j^2.\]
因此最佳叶子权重为
\[w_j^* = -frac{G_j}{H_j + lambda}.\]
这就是 XGBoost 版本的 -g/h 更新。正则化项 lambda 可以在 Hessian 很小时防止叶子分数变得过大。
对应的树结构评分为
\[-frac{1}{2}sum_{j=1}^{T}frac{G_j^2}{H_j + lambda} + gamma T.\]
当把一个叶子拆分为左、右两个子节点时,XGBoost 会评估增益:
\[text{Gain} = frac{1}{2}left[
frac{G_L^2}{H_L + lambda}
+ frac{G_R^2}{H_R + lambda}
- frac{(G_L + G_R)^2}{H_L + H_R + lambda}
right] - gamma.\]
当这个增益为正,并且足够大到可以证明额外复杂度是值得的,这次分裂就是有用的。这也是为什么 XGBoost 不只是“带树的梯度提升”;它是带有二阶信息、显式叶子评分和正则化分裂选择的梯度提升。
在 Python 中检查这些思想的一个最小方式是:
import numpy as np
# Binary labels and current probabilities from the current ensemble.
y = np.array([1, 0, 0, 1, 1], dtype=float)
p = np.array([0.55, 0.40, 0.48, 0.70, 0.62], dtype=float)
# Logistic-loss gradient and Hessian with respect to the log-odds score F.
g = p - y
h = p * (1 - p)
lambda_l2 = 1.0
leaf_weight = -g.sum() / (h.sum() + lambda_l2)
print(g)
print(h)
print(leaf_weight)具体数值取决于当前预测,以及哪些样本落入这个叶子。公式本身是稳定的:计算梯度,计算 Hessian,按叶子聚合它们,然后使用 -G / (H + lambda)。
Dana D. Sleep Data Personal Sleep Data from Sleep Cycle iOS App. Kaggle. https://www.kaggle.com/danagerous/sleep-data#
简体中文

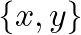 。如果把第四列作为标签,那么第三列就是特征;如果把第三列作为标签,那么第四列就是特征。
。如果把第四列作为标签,那么第三列就是特征;如果把第三列作为标签,那么第四列就是特征。