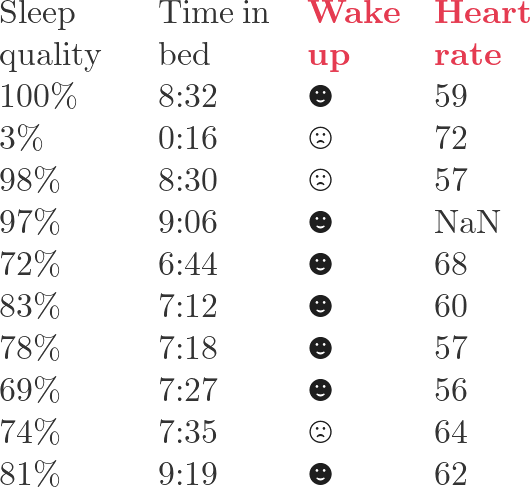
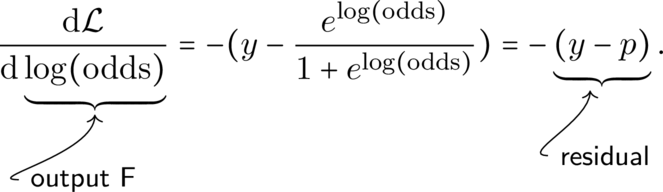このチュートリアル全体では、この単純なデータセット
ブースティングは加法的なモデリング戦略です。複雑なモデルを一度に1つ学習するのではなく、多数の単純なモデルを順番に学習します。新しい各モデルは、現在のアンサンブルがまだ間違えている部分を修正しようとします。
ステップ m 後の予測を次のように書きます。
\[F_m(x) = F_{m-1}(x) + eta f_m(x),\]
ここで F_{m-1} は現在のモデル、f_m は新しい弱学習器、eta は学習率です。木ブースティングでは、f_m は通常、回帰木です。重要なのは、この木が元の目的変数を直接学習するのではなく、現在の予測をどちらの方向へ動かすべきかを学習するという点です。
二乗誤差回帰では、この方向は簡単に確認できます。
\[L(y, F(x)) = frac{1}{2}(y - F(x))^2,\]
したがって負の勾配は
\[-frac{partial L}{partial F} = y - F(x).\]
これはまさに残差です。これが、勾配ブースティングを「次の木を残差にフィットさせる」と導入できる理由です。他の損失関数でも同じ考え方は機能しますが、その場合の残差は勾配から導かれる擬似残差になります。
勾配ブースティングの損失関数は次のように書けます。
\[mathcal{L}^{(t)} = sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right) + Omega(f_t).\]
ここで hat{y}_i^{(t-1)} は新しい木を追加する前の予測、f_t(x_i) は新しい木による更新、Omega(f_t) は正則化項です。直感をつかむため、まず正則化は無視します。
\[mathcal{L}^{(t)} approx sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right).\]
二乗誤差では、
\[l(y_i, hat{y}_i) = frac{1}{2}(y_i - hat{y}_i)^2.\]
現在の予測に関する微分は
\[frac{partial l}{partial hat{y}_i} = hat{y}_i - y_i.\]
したがって負の勾配は
\[y_i - hat{y}_i,\]
これは正確に残差です。したがって回帰ブースティングの1回の反復は次のようになります。
現在のアンサンブルで予測する。
残差または負の勾配を計算する。
その残差に新しい木をフィットさせる。
通常は学習率を掛けて、その木をアンサンブルに追加する。
これにより、通常の残差フィッティングから勾配ブースティングへの橋渡しが説明できます。残差は負の勾配の特殊な場合なのです。
注意: 記法が重くなるのを避けるため、以下では総和記号 sum を省略することがあります。導出は二値分類を対象としています。
二値分類問題では、オッズを次のように定義します。
\[text{odds} = frac{text{win}}{text{lose}}.\]
確率は
\[p = frac{text{win}}{text{win}+text{lose}}.\]
簡単な代数により、
\[p = frac{text{odds}}{1 + text{odds}}
= frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}.\]
これはロジット、つまり対数オッズにロジスティックシグモイドを適用したものです。次のように置きます。
\[F_m = log(text{odds}) = F_{m-1} + gamma.\]
すると、
\[p = frac{e^{F_m}}{1 + e^{F_m}}.\]
損失として二値交差エントロピーを使います。
\[begin{aligned}
mathcal{L}(y, F_{m-1} + gamma)
&= -left[ylog(p) + (1-y)log(1-p)right]
&= -left[yleft(log(p)-log(1-p)right) + log(1-p)right]
&= -left[ylogfrac{p}{1-p} - log(1+text{odds})right]
&= -left[ylog(text{odds}) - logleft(1+e^{log(text{odds})}right)right].
end{aligned}\]
損失を最小化する gamma を見つけたいとします。
\[operatorname*{arg,min}_{gamma}; mathcal{L}.\]
損失を直接扱って
\[frac{partial mathcal{L}}{partial gamma} = 0,\]
を解くこともできますが、これは煩雑になります。2次のテイラー近似を使うと、更新がより明快になります。現在のスコア F_{m-1} の周りで、
\[mathcal{L}(y, F_{m-1}+gamma)
approx
mathcal{L}(y, F_{m-1})
+ ggamma
+ frac{1}{2}hgamma^2,\]
ここで、
\[g = frac{partial mathcal{L}}{partial F},
qquad
h = frac{partial^2 mathcal{L}}{partial F^2}.\]
gamma に関する微分をゼロにします。
\[frac{partial}{partial gamma}left(mathcal{L}(y, F_{m-1}) + ggamma + frac{1}{2}hgamma^2right) = 0.\]
これにより、
\[g + hgamma = 0,\]
となるので、局所的な最適更新は
\[gamma = -frac{g}{h}.\]
二値交差エントロピーでは、F = log(text{odds}) に関する1階微分は
\[frac{partial mathcal{L}}{partial log(text{odds})}
= -left(y - frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}right)
= p-y.\]
少し図示すると、
log(text{odds}) に関する mathcal{L} の2階微分は
\[begin{aligned}
frac{partial^2 mathcal{L}}{partial log(text{odds})^2}
&= frac{partial}{partial log(text{odds})}
frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}
&= frac{e^{log(text{odds})}(1 + e^{log(text{odds})}) - e^{2log(text{odds})}}{(1 + e^{log(text{odds})})^2}
&= frac{1}{1 + e^{log(text{odds})}}
frac{e^{log(text{odds})}}{1 + e^{log(text{odds})}}
&= p(1-p).
end{aligned}\]
したがって、1つの観測値については、
\[gamma = -frac{p-y}{p(1-p)} = frac{y-p}{p(1-p)}.\]
多くの観測値を含む葉では、ニュートン法風の更新は勾配とヘッセ行列成分を集約します。
\[gamma_j = -frac{sum_{i in I_j} g_i}{sum_{i in I_j} h_i}.\]
これが、分類の勾配ブースティングからXGBoostへの実践的な橋渡しです。
XGBoostは加法的な木モデルを維持しつつ、目的関数をより明示的かつ正則化された形にします。ブースティングラウンド t では、次を最小化します。
\[mathcal{L}^{(t)} = sum_{i=1}^n lleft(y_i, hat{y}_i^{(t-1)} + f_t(x_i)right) + Omega(f_t),\]
ここで木の正則化は一般に次のように書かれます。
\[Omega(f) = gamma T + frac{1}{2}lambdasum_{j=1}^{T} w_j^2.\]
ここで T は葉の数、w_j は葉 j のスコア、gamma は葉を追加することへのペナルティ、lambda は葉の重みに対するL2正則化です。
2次のテイラー近似を使うと、
\[mathcal{L}^{(t)} approx
sum_{i=1}^{n}left[g_i f_t(x_i) + frac{1}{2}h_i f_t(x_i)^2right] + Omega(f_t),\]
ここで、
\[g_i = frac{partial l(y_i, hat{y}_i^{(t-1)})}{partial hat{y}_i^{(t-1)}},
qquad
h_i = frac{partial^2 l(y_i, hat{y}_i^{(t-1)})}{partial (hat{y}_i^{(t-1)})^2}.\]
固定された木構造では、各サンプルは1つの葉に入ります。I_j を葉 j に含まれるサンプル集合とし、次のように定義します。
\[G_j = sum_{i in I_j} g_i,
qquad
H_j = sum_{i in I_j} h_i.\]
葉 j の目的関数は
\[G_j w_j + frac{1}{2}(H_j + lambda)w_j^2.\]
したがって最良の葉重みは
\[w_j^* = -frac{G_j}{H_j + lambda}.\]
これは -g/h 更新のXGBoost版です。正則化項 lambda は、ヘッセ行列成分が小さいときに葉スコアが非常に大きくなるのを防ぎます。
対応する木構造のスコアは
\[-frac{1}{2}sum_{j=1}^{T}frac{G_j^2}{H_j + lambda} + gamma T.\]
1つの葉を左右の子に分割するとき、XGBoostは次のゲインを評価します。
\[text{Gain} = frac{1}{2}left[
frac{G_L^2}{H_L + lambda}
+ frac{G_R^2}{H_R + lambda}
- frac{(G_L + G_R)^2}{H_L + H_R + lambda}
right] - gamma.\]
このゲインが正で、追加の複雑さを正当化できるほど十分に大きい場合、その分割は有用です。これが、XGBoostが単なる「木を使った勾配ブースティング」ではない理由です。XGBoostは、2階情報、明示的な葉スコアリング、そして正則化された分割選択を備えた勾配ブースティングなのです。
Pythonでこれらの考え方を最小限に確認する方法は次のとおりです。
import numpy as np
# Binary labels and current probabilities from the current ensemble.
y = np.array([1, 0, 0, 1, 1], dtype=float)
p = np.array([0.55, 0.40, 0.48, 0.70, 0.62], dtype=float)
# Logistic-loss gradient and Hessian with respect to the log-odds score F.
g = p - y
h = p * (1 - p)
lambda_l2 = 1.0
leaf_weight = -g.sum() / (h.sum() + lambda_l2)
print(g)
print(h)
print(leaf_weight)正確な数値は、現在の予測と、どのサンプルがその葉に入るかに依存します。式は安定しています。勾配を計算し、ヘッセ行列成分を計算し、それらを葉ごとに集約してから、-G / (H + lambda) を使います。
Dana D. Sleep Data Personal Sleep Data from Sleep Cycle iOS App. Kaggle. https://www.kaggle.com/danagerous/sleep-data#
日本語

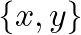 を使います。4列目をラベルとして使うなら3列目が特徴量になり、3列目をラベルとして使うなら4列目が特徴量になります。
を使います。4列目をラベルとして使うなら3列目が特徴量になり、3列目をラベルとして使うなら4列目が特徴量になります。