
Table of Contents
はじめに
物理学はパターンの学問である。繰り返される観測は簡潔な法則へとまとめられ、その法則は予測によって検証される。Python はこの作業の流れで有用である。記号的な推論、数値シミュレーション、可視化、機械学習のあいだを、頻繁に道具を替えずに行き来できるからだ。
このノートでは、物理の考え方から計算手法へ至る実践的な地図を描く。教科書の代わりではないが、コードを使って物理を学ぶための構造を与える。モデルを特定し、数学的対象を書き下し、厳密計算が不可能なときには近似を選び、結果を単位、極限の場合、既知の例と照合する、という流れである。
パターン認識と機械学習
パターン認識はデータから始まる。物理では、そのデータは振動子から得られる時系列、実験から得られるスペクトル、粒子飛跡の集合、あるいはモデルから生成されたシミュレーション標本かもしれない。基本的なワークフローは安定している。
- 観測量とその単位を定義する。
- 信号を壊さずにデータをクリーニングする。
- モデルのクラスを選ぶ。
- 訓練データでパラメータをフィットする。
- 保留データまたは既知の物理的極限で検証する。
- 残差と不確かさを調べる。
機械学習は、入力から出力への写像を明示的に書くのが難しいときに役立つ。たとえばニューラルネットワークは、配置から物質の相を分類したり、ポテンシャルエネルギー面を近似したり、高価なシミュレーションの代理モデルを学習したりできる。重要な注意点は、予測器として成功していることが、そのまま物理的説明であるとは限らないということだ。物理モデルは、保存則、対称性、次元の整合性、因果性といった制約も満たすべきである。
Python での最小限の再現可能な確認では、物理モデルをフィッティングのコードから分離する。
import numpy as np
from sklearn.linear_model import LinearRegression
# Example: y = a x + b with noisy observations.
rng = np.random.default_rng(42)
x = np.linspace(0, 10, 100)
y = 2.5 * x - 1.0 + rng.normal(scale=0.8, size=x.shape)
model = LinearRegression()
model.fit(x.reshape(-1, 1), y)
print(model.coef_[0], model.intercept_)結果を信頼する前に、フィットされたパラメータが期待される次元を持つか、残差に構造が現れていないかを確認する。残差にパターンがあるなら、そのモデルには物理が欠けている。
古典物理
古典物理は自然な出発点である。多くの系が、位置、速度、力、場、エネルギーによって記述できるからだ。ニュートン力学はよく知られた方程式を与える。
F = m a位置 x(t) を持つ系では、計算問題はしばしば常微分方程式を解くことになる。減衰振動子では、
m x'' + c x' + k x = 0これを一階方程式に書き換えることで、数値的に積分できる。
import numpy as np
from scipy.integrate import solve_ivp
m = 1.0
c = 0.2
k = 4.0
def oscillator(t, state):
x, v = state
dxdt = v
dvdt = -(c / m) * v - (k / m) * x
return [dxdt, dvdt]
solution = solve_ivp(
oscillator,
t_span=(0.0, 20.0),
y0=[1.0, 0.0],
max_step=0.05,
)
print(solution.t.shape, solution.y.shape)同じパターンは電磁気学、流体力学、連続体力学にも現れる。支配方程式を書き、境界条件と初期条件を選び、数値手法を選択し、可能なところでは保存性や安定性を検証する。
有用な確認には次のようなものがある。
c = 0の極限では、振動子はエネルギーを保存するはずである。- 時間刻みを小さくしても、結果が根本的に変わるべきではない。
- パラメータは整合した単位を持つべきである。
- 数値的アーティファクトを物理効果と取り違えてはならない。
量子力学と量子コンピューティング
量子力学は決定論的な軌道を、状態、演算子、振幅、測定確率へと置き換える。純粋状態はベクトル |psi> で表され、観測量は演算子で表される。シュレーディンガー方程式は時間発展を記述する。
i hbar d|psi>/dt = H |psi>有限次元の系では、ハミルトニアン H は行列として表せる。二準位系は最も単純で有用な例である。
import numpy as np
from scipy.linalg import expm
hbar = 1.0
sigma_x = np.array([[0, 1], [1, 0]], dtype=complex)
H = 0.5 * sigma_x
psi0 = np.array([1, 0], dtype=complex)
def evolve(t):
U = expm(-1j * H * t / hbar)
return U @ psi0
psi_t = evolve(np.pi)
probabilities = np.abs(psi_t) ** 2
print(probabilities)量子コンピューティングは、制御された量子時間発展を計算資源として用いる。量子ビットは二準位の量子系であり、ゲートはユニタリ操作である。実践上の問いはたいてい次のようなものになる。
- 状態はどのように準備されるか。
- どのユニタリ操作が適用されるか。
- どの測定が行われるか。
- 結果を推定するには何回のサンプルが必要か。
- どのノイズモデルが関係するか。
量子コンピューティングのライブラリを使うときは、インストール済みのバージョンをローカルで確認し、現在のドキュメントを読むこと。API や対応デバイスは時間とともに変わるからである。
相対論とテンソル
相対論は、座標系のあいだで一貫して変換される対象を中心に構築される。テンソルはそのための言語を与える。一般相対論では、時空の曲率はアインシュタイン方程式によってエネルギーと運動量に関係づけられる。
(1) 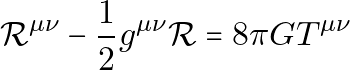
ここで g は計量テンソル、R は曲率、T はエネルギー運動量テンソル、G はニュートンの重力定数である。この方程式は簡潔だが、解くには通常、対称性の仮定、近似、あるいは数値相対論が必要になる。
テンソル記法は、成分がどのように変換されるかを追跡する。たとえば次のように書ける。
(2) 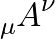
実践的な計算上の習慣は、抽象的な対象をその座標表示から分けて考えることだ。たとえば計量テンソルを扱うときには、次を確認する。
- 使用している座標チャート。
- 計量の符号規約。
- 添字が共変か反変か。
cなどの定数を1にしているか。- 単位が幾何化単位系か SI か。
テンソル用パッケージは添字操作を自動化できるが、規約を理解する必要をなくしてくれるわけではない。
宇宙論と天体物理
宇宙論は、一般相対論、熱力学、核物理、統計的推論を宇宙全体に適用する。標準的な大スケールモデルは一様性と等方性を仮定し、それによってフリードマン・ルメートル・ロバートソン・ウォーカー計量とフリードマン方程式が導かれる。
天体物理は幅広いスケールを扱う。恒星構造、コンパクト天体、銀河、重力波、宇宙背景放射などである。Python は、単位、座標変換、カタログ処理、フィッティング、可視化に広く使われている。
長く使える計算上の習慣は、単位を明示することである。たとえば astropy では次のように書ける。
from astropy import units as u
from astropy.constants import G, M_sun
mass = 1.0 * M_sun
radius = 6.96e8 * u.m
escape_velocity = (2 * G * mass / radius) ** 0.5
print(escape_velocity.to(u.km / u.s))この書き方は、多くの気づきにくい誤りを防ぐ。数値はもっともらしく見えても、単位が間違っていることがある。
統計力学
統計力学は、微視的状態と、温度、エントロピー、圧力、自由エネルギーなどの巨視的量を結びつける。中心的な対象はしばしば分配関数である。
Z = sum_i exp(-beta E_i)ここで beta = 1 / (k_B T) である。Z が分かれば、熱力学量をそこから導ける。小さな系では、和を直接計算できる。
import numpy as np
k_B = 1.0
T = 2.0
beta = 1.0 / (k_B * T)
energies = np.array([0.0, 1.0, 2.0, 4.0])
weights = np.exp(-beta * energies)
Z = weights.sum()
probabilities = weights / Z
mean_energy = np.sum(probabilities * energies)
print(Z, probabilities, mean_energy)大きな系では、直接列挙は不可能になる。その場合は、モンテカルロ法、分子動力学、近似手法が用いられる。いつものように、数値結果は極限の場合と照合すべきである。高温、低温、小さな系サイズ、あるいは解析的に解けるモデルなどである。
Python による実装
Python が有用なのは、そのエコシステムが物理の作業の複数の層をカバーしているからである。
- 配列と線形代数には
NumPy。 - 積分、最適化、疎行列、特殊関数には
SciPy。 - プロットには
Matplotlib。 - 記号数学には
SymPy。 - 標準的な機械学習ワークフローには
scikit-learn。 - 量子力学、相対論、天体物理、熱力学のためのドメインライブラリ。
信頼できる環境は、隔離された仮想環境と明示的な依存関係から始まる。
python -m venv .venv
source .venv/bin/activate
python -m pip install --upgrade pip
python -m pip install numpy scipy matplotlib sympy scikit-learn次に、ローカルでバージョンを確認する。
python - <<'PY'
import numpy, scipy, sympy
print('numpy', numpy.__version__)
print('scipy', scipy.__version__)
print('sympy', sympy.__version__)
PYPennyLane
PennyLane は微分可能な量子プログラミングのための Python ライブラリである。量子回路を最適化や機械学習と組み合わせる実験に役立つ。典型的なワークフローは次のとおりである。
- デバイスまたはシミュレータを選ぶ。
- 量子ノードを定義する。
- パラメータ化された回路を構築する。
- 期待値を評価する。
- 古典的オプティマイザでパラメータを最適化する。
量子ソフトウェアは急速に変化するため、常にインストール済みのバージョンと対応デバイスをローカルで確認すること。
SymPy
SymPy は、数値結果と同じくらい数式そのものが重要なときに役立つ。式の簡約、記号微分、方程式の求解、数値関数の生成ができる。
import sympy as sp
x, k, m = sp.symbols('x k m', positive=True)
V = sp.Rational(1, 2) * k * x**2
force = -sp.diff(V, x)
print(force)記号計算は、数値実装に移る前に方程式を導出するとき、とくに有用である。
QuTiP、einsteinpy、astropy、thermopy
QuTiP は量子ダイナミクスと開放量子系に使われる。密度行列、マスター方程式、量子演算子が中心になる場合に有用である。
einsteinpy は、測地線、計量、記号的テンソル演算などの相対論計算に焦点を当てている。
astropy は天文学と天体物理のための成熟したライブラリであり、とくに単位、座標、定数、時刻、データ形式に強い。
thermopy は熱力学計算に使われる。プロジェクトで依存する前に、現在のメンテナンス状況と自分の Python バージョンとの互換性を確認すること。
どのドメインパッケージでも、実践的な規則は同じである。隔離された環境にインストールし、現在のドキュメントにある最小例を実行し、既知の結果を確認する小さな検証テストを書くこと。